
Los recientes modelos de lenguaje extenso (LLM) han logrado avances notables, con ejemplos notables como GPT-3, PaLM, LLaMA, ChatGPT y el T-4 propuesto más recientemente. Estos modelos tienen un gran potencial para la planificación y la toma de decisiones similares a las de los humanos. Los LLM muestran habilidades emergentes, incluido el aprendizaje en contexto, el razonamiento matemático y el pensamiento de sentido común. Sin embargo, tienen algunas restricciones.
Recent large language models (LLMs) for diverse NLP tasks have made remarkable strides, with notable examples being GPT-3, PaLM, LLaMA, ChatGPT, and the more recently proposed GPT-4. These models have enormous promise for planning and making decisions similar to humans since they can solve various tasks in zero-shot situations or with the help of a few instances. Emergent skills, including in-context learning, mathematical reasoning, and common sense thinking, are shown by LLMs. However, LLMs have built-in constraints, such as the inability to use external tools, access current information, or reason mathematically with precision.
An ongoing research area focuses on enhancing language models with access to outside tools and resources and investigating the integration of outdoor tools and plug-and-play modular strategies to solve these constraints of LLMs. Recent research uses LLMs to construct complicated programs that more efficiently complete logical reasoning problems and leverage strong computer resources to improve mathematical reasoning abilities. For instance, with the help of external knowledge sources and online search engines, LLMs can acquire real-time information and use domain-specific knowledge. Another current line of research, including ViperGPT, Visual ChatGPT, VisProg, and HuggingGPT, integrates several basic computer vision models to give LLMs the skills necessary to handle visual reasoning problems.
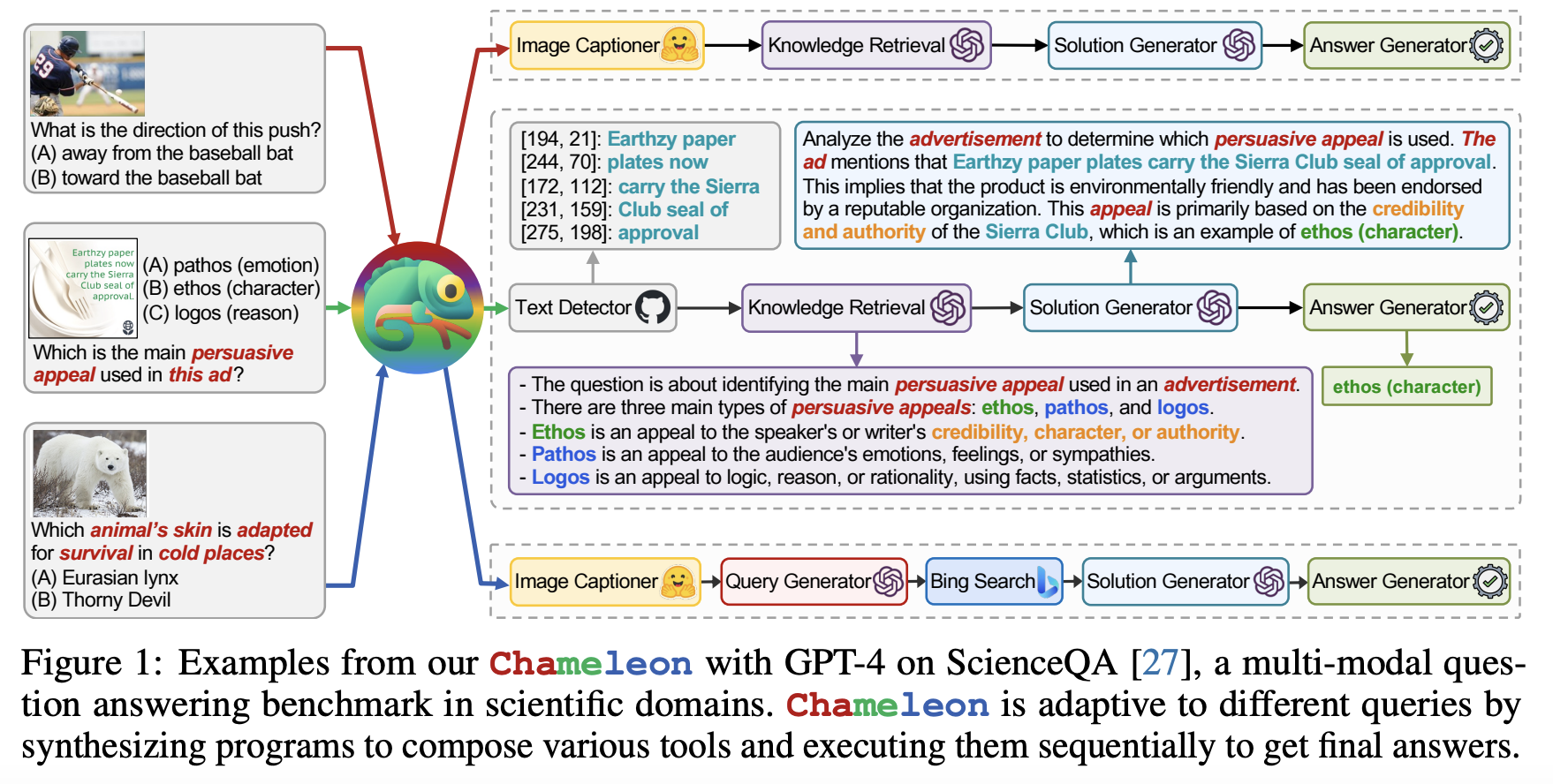
Despite substantial advancements, today’s tool-augmented LLMs still encounter major obstacles while responding to real-world inquiries. Most current techniques are restricted to a narrow set of tools or rely on particular devices for a given domain, making it difficult to generalize them to different inquiries. Figure 1 illustrates this: “Which is the main persuasive appeal used in this ad?” 1) Assume that an advertisement picture has text context and call a text decoder to comprehend the semantics to respond to this query; 2) find background information to explain what “persuasive appeal” is and how different types differ; 3) come up with a solution using the hints from the input question and the interim outcomes from earlier phases; and 4) finally, present the response in a task-specific manner.
On the other hand, while responding to the question “Which animal’s skin is adapted for survival in cold places,” one might need to contact additional modules, such as an image captioner to parse picture information and a web search engine to collect domain knowledge to grasp scientific terminology. Researchers from UCLA and Microsoft Research provide Chameleon, a plug-and-play compositional reasoning framework that uses huge language models to solve these problems. Chameleon can synthesize programs to create various tools to answer multiple questions.
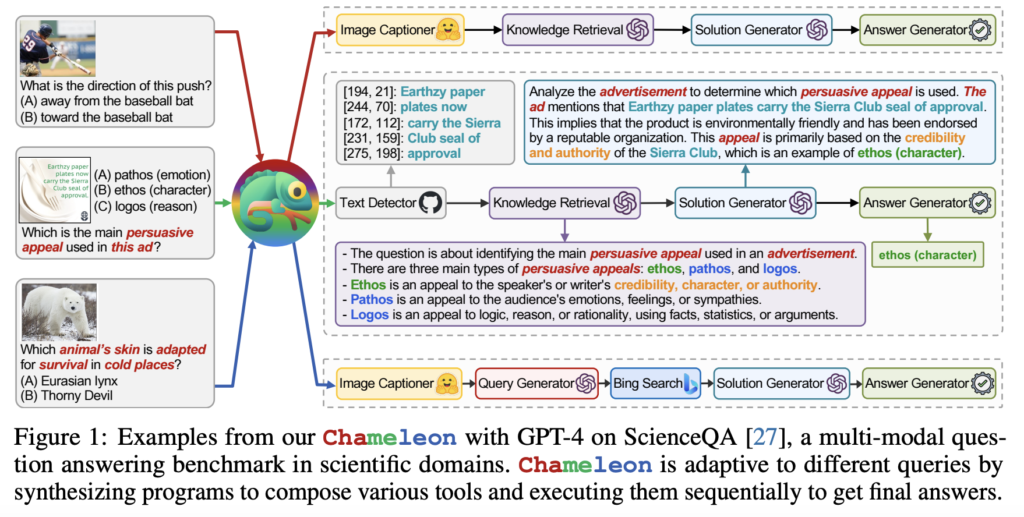
Chameleon is a natural language planner that builds upon an LLM. Contrary to conventional methods, it uses various tools, such as LLMs, pre-built computer vision models, online search engines, Python functions, and rule-based modules designed for a particular goal. Chameleon generates these programs using the in-context learning capabilities of LLMs and does not need any training. The planner can deduce the proper order of tools to compose and run to provide the final response to a user inquiry, prompted by descriptions of each tool and examples of tool usage.
Chameleon creates programs that resemble natural language, unlike earlier efforts that made domain-specific programs. These programs are less error-prone, simpler to debug, more user-friendly for individuals with little programming knowledge, and expandable to include new modules. Each module in the program executes, processes, and caches the query and context, returns a response chosen by the module, and modifies the query and stored context for upcoming module executions. By composing modules as a sequential program, updated queries and previously cached context may be used throughout the execution of the next modules. On two tasks—ScienceQA and TabMWP—they demonstrate Chameleon’s flexibility and potency.
TabMWP is a mathematics benchmark including numerous tabular contexts, whereas ScienceQA is a multi-modal question-answering benchmark encompassing many context formats and scientific themes. The effectiveness of Chameleon’s capacity to coordinate various tools across various types and domains may be tested using these two benchmarks. Notably, Chameleon with GPT-4 obtains an accuracy of 86.54% on ScienceQA, outperforming the best-reported few-shot model by a factor of 11.37%. Chameleon delivers an improvement of 7.97% over CoT GPT-4 and a 17.8% increase over the state-of-the-art model on TabMWP utilizing GPT-4 as the underlying LLM, resulting in a 98.78% total accuracy.
Compared to previous LLMs like ChatGPT, further research suggests that employing GPT-4 as a planner demonstrates more consistent and logical tool selection and can deduce probable restrictions given the instructions. Their brief contributions are as follows: (1) They create Chameleon, a plug-and-play compositional reasoning framework, to solve the inherent limits of huge language models and take on various reasoning tasks. (2) They effectively combine several technologies, including LLMs, commercial vision models, online search engines, Python functions, and rule-based modules, to create a flexible and adaptive AI system to respond to real-world inquiries. (3) They considerably advance the state of the art by demonstrating the framework’s flexibility and efficacy on two -benchmarks, ScienceQA and TabMWP. The codebase is publicly available on GitHub.
Fuente: https://www.marktechpost.com