

Las alucinaciones del modelo de lenguaje grande (LLM), es decir, los modelos que producen resultados incorrectos, son el mayor obstáculo para la adopción del LLM. Los humanos no podrán delegar trabajo de manera constante a los sistemas de inteligencia artificial hasta que puedan confiar en que el resultado del LLM sea correcto.
Large Language Model (LLM) hallucinations, i.e., models producing wrong outputs, are the biggest obstacle to LLM adoption. Humans will not be able to consistently offload work to AI systems until they are able to trust the output of the LLM to be correct.
For instance, while triaging patients on easy questions might help offload a lot of work for hospitals, hallucinations of symptoms and answers from AI Agents will prevent such models from being used in practice. Therefore, knowing when to trust an AI and when to have humans in the loop is critical if we want to deploy such models in large-scale and impactful settings.
We recently ran an experiment to assess the performance of SelfCheckGPT NLI, a measure of LLM inconsistencies, to predict hallucinated outputs.
Our key findings are:
- This indicator is highly precise after a certain threshold, aka any flagged hallucination, is actually a hallucination.
- The recall (hallucination detection) rate was well calibrated with the SelfCheckGPT score. A SelfCheckGPT NLI score of 0.8 corresponds to close to 80% of the hallucinations being identified.
We conclude that SelfCheckGPT NLI can be a trustworthy metric for hallucinations and encourage efforts from the community to pursue the development of such metrics for the deployment of LLMs in production.
Our experiment can be reproduced using our notebook.
On our Hugging Face Space, we released a demo where you can see first-hand the results of the SelfCheckGPT NLI score as an indicator of hallucination detection with example texts while adjusting a detection threshold level.
Mithril Security
We conducted these tests as part of our mission to build Confidential and Trustworthy Conversational AI. You can check out our core project, BlindChat, an open-source and Confidential Conversational AI (aka any data sent to our AI remains private, and not even our admins can see your prompts) at chat.mithrilsecurity.io.
If you’d like to see us integrate automatic hallucination detection into our product, please register your interest in this feature here.
Hallucinations: An enduring barrier to LLM uptake
While LLMs show tremendous potential, hallucinations are still an unsolved issue that can prevent the deployment of LLMs at scale.
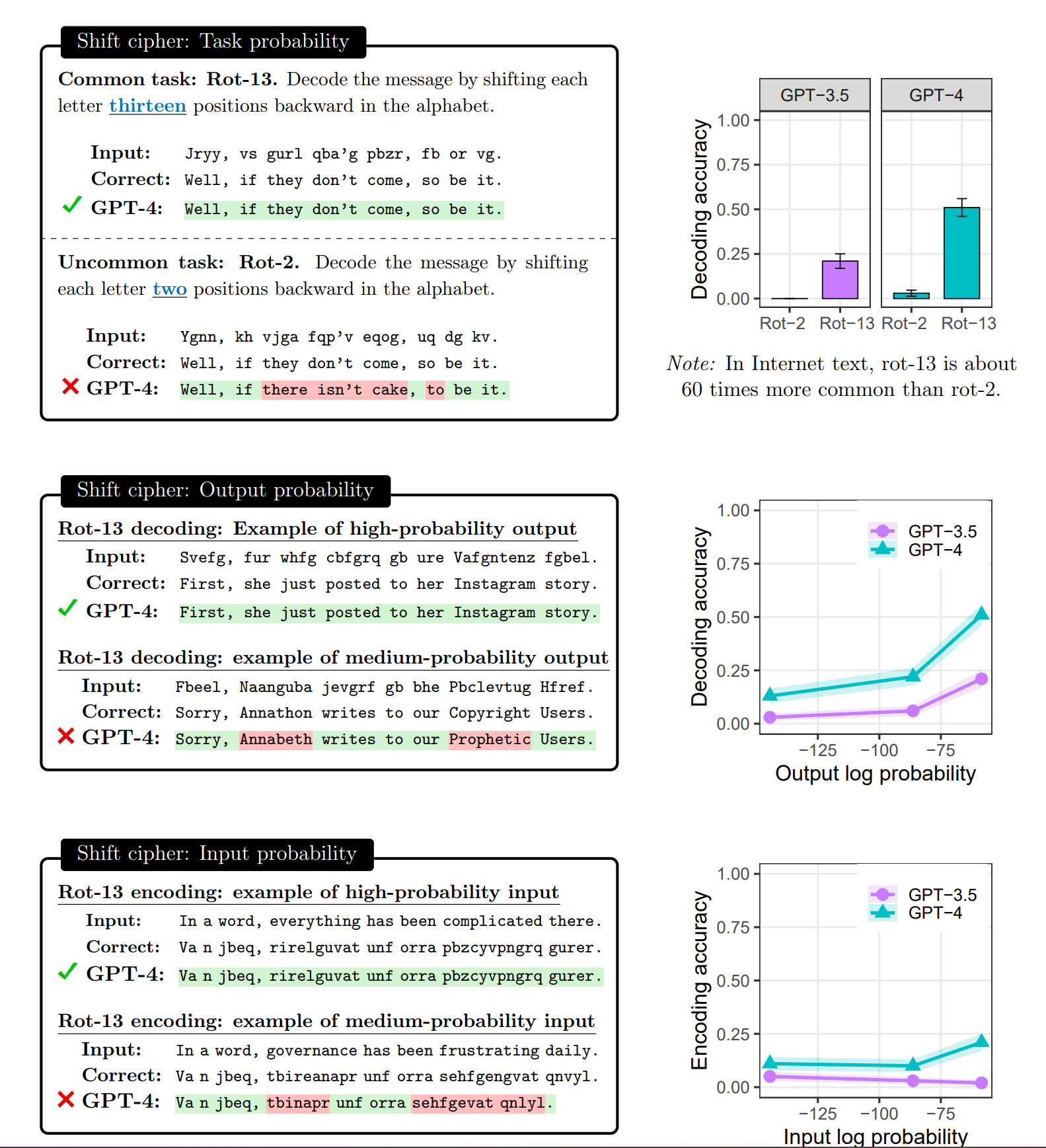
As described in a recent paper by Mccoy et al., hallucinations occur when LLMs are asked to answer prompts whose task, input or output were not present in the training set. The LLM therefore produces an answer which is not based on any ground truth, or information that is known to be true.
This is logical when we consider that LLMs are taught to produce the most probable next token according to the distribution of their training set.
To give an example from the aforementioned study, when asked to perform Cesar Cipher of 13 (a well-known basic encryption of text by shifting every letter by 13 places in the alphabet), GPT4 has relatively good accuracy. However, when asked to perform a Cesar Cipher of 2 (shifting each letter by 2 places), its accuracy decreases from 0.5 to almost 0. They conclude that this is most likely due to the abundance of examples of Cesar Cipher with a shift of 13, compared to a shift of 2 (doing two Cesar Cipher of 13 leads back to the original text).
We see the same decline in accuracy where the expected answer/prompt is not present in the training dataset.
This means that unlikely outputs, i.e., ones where the next token has a low confidence score (a.k.a, the most likely next token has a low probability in absolute), will most likely be false, and responses to the same query performed several times will generate inconsistent results.
Automatic hallucination detection with SelfCheckGPT
This insight is leveraged by SelfCheckGPT (Manakul, P., Liusie, A., & Gales, M. J. F. (2023). SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models.), as several samples of the same prompt are drawn, and used to detect inconsistencies among them. The higher the inconsistencies, the more likely the LLM is hallucinating.
The way SelfCheckGPT NLI provides a hallucination score for a given prompt to a given LLM (e.g. GPT4 or any open-source LLM):

Note that the SelfCheckGPT NLI score has several advantages:
- It works in a black-box setting, aka there is no need to have access to the weights or the log probabilities, which means it works with both closed-source models being APIs or fully transparent open-source models
- It works for free text generation, aka it covers almost any task, be it summarization, question answering in free form, or classification
The reason why such an inconsistency score can be used to detect hallucinations automatically is the following:
- The less seen in the training set a specific task is, the more the LLM will be hallucinating (cf. the Embers of autoregression paper mentioned earlier)
- The less a specific task is seen in the training set, the less confident the LLM will be in the next token to choose (aka higher entropy and the most likely token will have a low score, let’s say 0.3, versus a very certain output of 0.9)
- The higher the entropy, the more diverse and inconsistent different samples from the same prompt will be
- The more inconsistent the samples, the higher a metric that looks at the inconsistency between sentences, like SelfCheckGPT NLI score, is
For our experiment, we provide a Colab notebook to show how performant and calibrated SelfCheckGPT is for detecting hallucinations. We will evaluate it on the Wiki Bio hallucination dataset, which has been curated by the authors of SelfCheckGPT.
To test whether or not a model is hallucinating, they constructed a dataset where they asked GPT-3 to generate a description of topics with the prompt format “This is a Wikipedia passage about {concept}:”, recorded the output, and then manually labeled each sentence of the generated text by humans to have a gold standard about factuality. The labels were “Accurate” (0), “Minor Inaccurate” (0.5), and “Major Inaccurate” (1).
Then they generated N=20 additional samples, that will be used to detect hallucination through inconsistency scoring.
In our notebook, we have computed the SelfCheckGPT NLI score (using DeBERTA as the NLI model) for each sentence and flagged it as a hallucination if the score was higher than some threshold (here 0.35).
We have then plotted calibrated plots of precision and recall.
Explanation of calibration
Calibration is key in building trust in a model. Ideally, when a model provides a 0.8 probability score that a given sample is a hallucination, one would like it to be the case that this prediction would hold true 80% of the time.
As hallucination labeling could happen in imbalanced settings, for instance, if we ask the LLM to perform easy vs hard tasks, precision and recall are more relevant.
That is why we will look at precision and recall for different probability scores.
Hallucination recall conveys the number of hallucinations that are detected by our model for a given data set. If the recall is 0.8, it means that we have properly flagged 80% of the hallucinations.
Hallucination precision conveys how often predicted hallucinations actually are hallucinations and not false positives. An accuracy of 0.8 would mean that 80% of the time when we say a sentence is a hallucination, it is indeed one.
We have obtained the following calibrated plots:
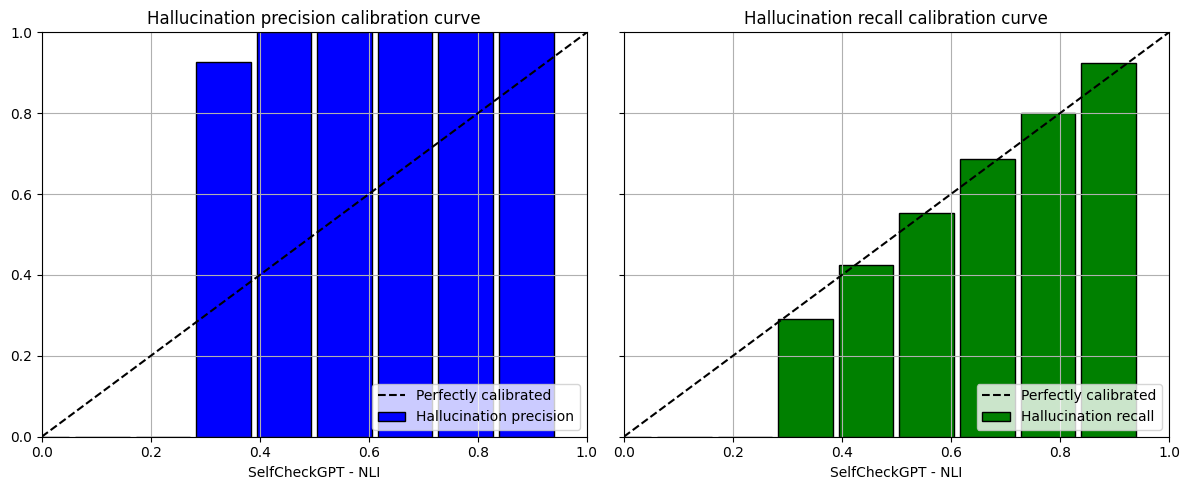
So what can be an interpretation of these plots?
We see that our model is extremely precise in detecting hallucinations once the score is above 0.5. It reaches perfect precision, which means that whenever it makes the prediction that a sentence is a hallucination, it is almost certain it is actually the case!
But being precise is not enough, if a model is conservative and only flags a few sentences as hallucinations, then this model would not be very useful. That is why we need to have a look at recall too.
Interestingly, the recall score seems to be calibrated with the probability of hallucination: the higher the probability the higher the recall!
This means that for instance, for an NLI score of 0.8, this model will flag 80% of the hallucinations as the recall is close to 80%, and all examples flagged are actually hallucinations as the precision is 1.0.
This is great! It means that we can have a trustworthy metric for hallucination, as it is able to both:
- Provide a calibrated ability to flag hallucinations, aka the higher the hallucination score, the higher the likelihood to find hallucinations (calibrated recall)
- Be extremely precise in its prediction, aka not falsely labeling truthful sentences as hallucinations (perfect precision)
Both of those properties mean that we can now reliably and automatically detect hallucinations. This means we could either verify the trustworthiness of an answer in a chat, and when an hallucination is detected, notify the user that extra checks must be performed.
Before concluding, one might think that this is great but how about the cost of such metric?
In the initial SelfCheckGPT paper, they sampled N=20 more answers, on top of the original prediction, to predict the hallucination score.
This is, therefore quite expensive and impractical as it would drastically increase cost and time.
Therefore, one could think, are that many samples needed?
To study that, we varied the number of samples used to compute the NLI score, and plotted the same graphs with N=3, 10, 20:
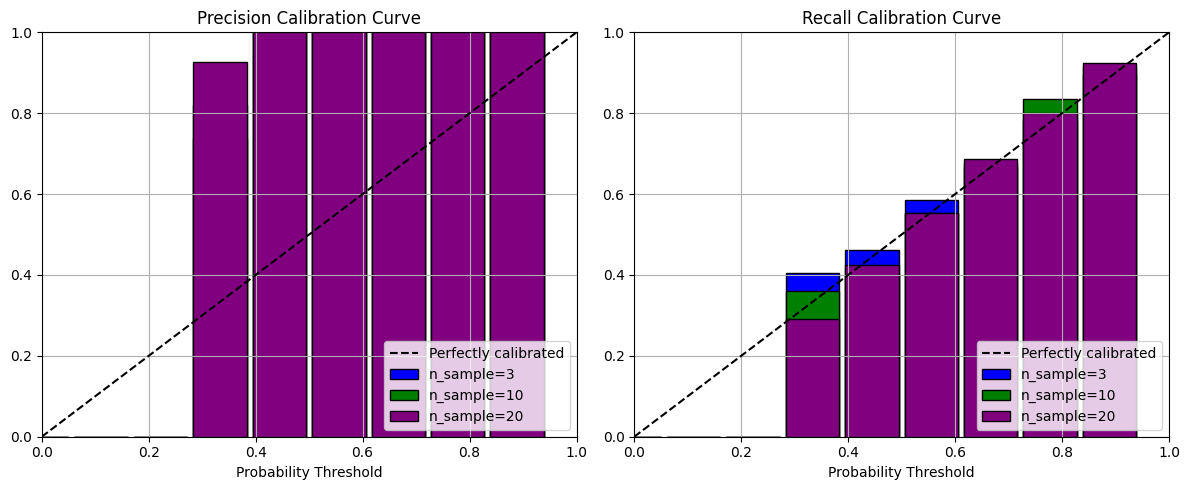
While we can observe slight differences, the overall behavior is the same, even for N=3.
While still being a high number and multiplying the cost by 4, this initial work provides a first lead towards a practical, generic, and automatic way to detect hallucinations to build Trustworthy AI systems.
We have deployed a Gradio demo to let you see in practice how we can use SelfCheckGPT to detect hallucinations.
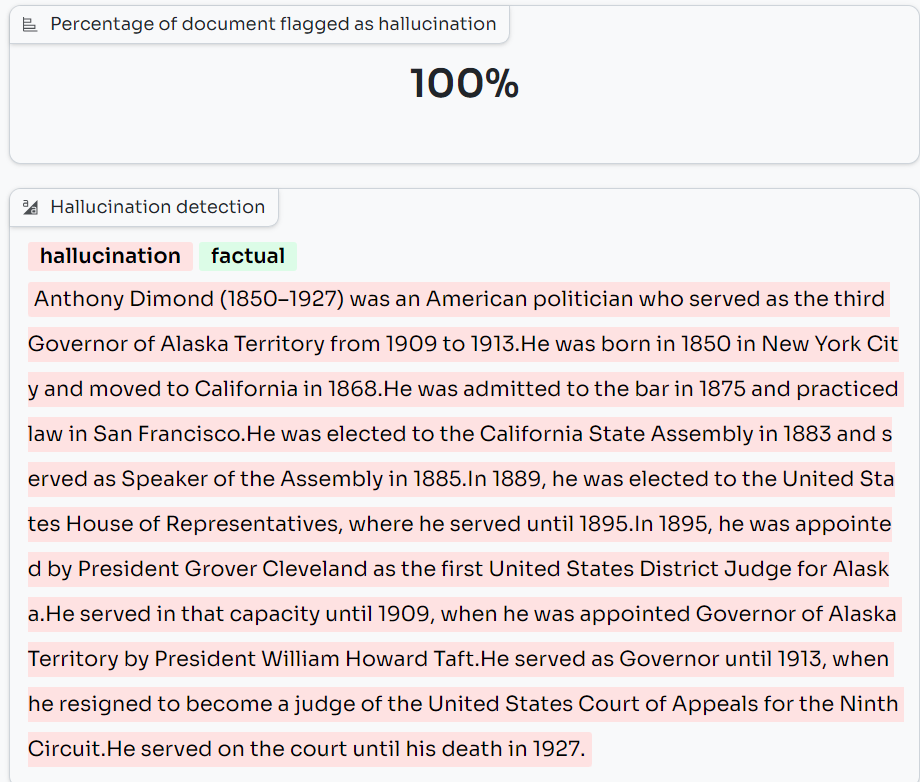
On the left-hand side, you can select one of six examples. They are grouped into low and high hallucination samples. You can also select a detection threshold, which sets the minimum SelfCheckGPT NLI score required for a sentence to be flagged as a hallucination. You can play with this threshold value to explore how it impacts the balance between False Positive and False Negative.
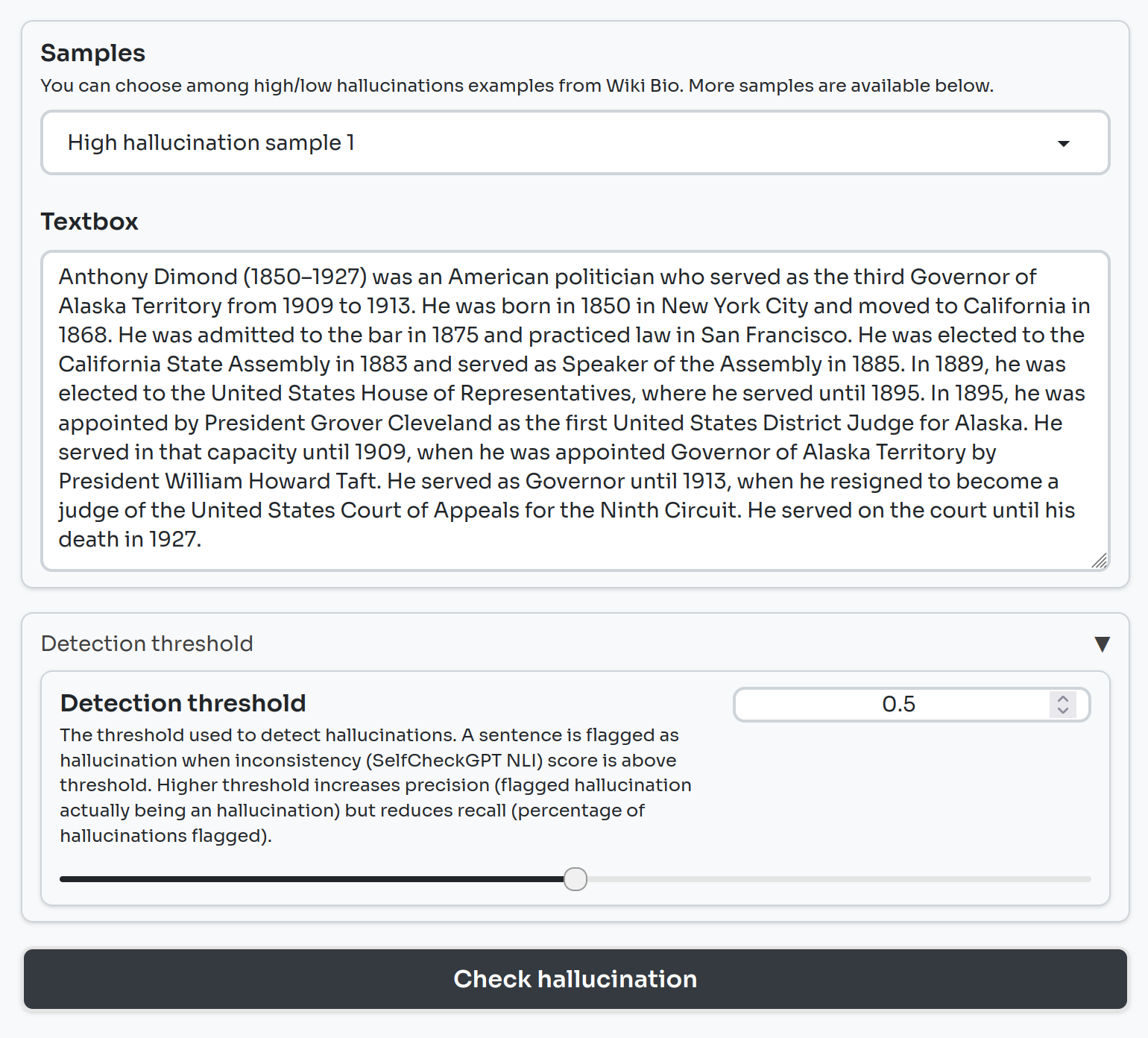
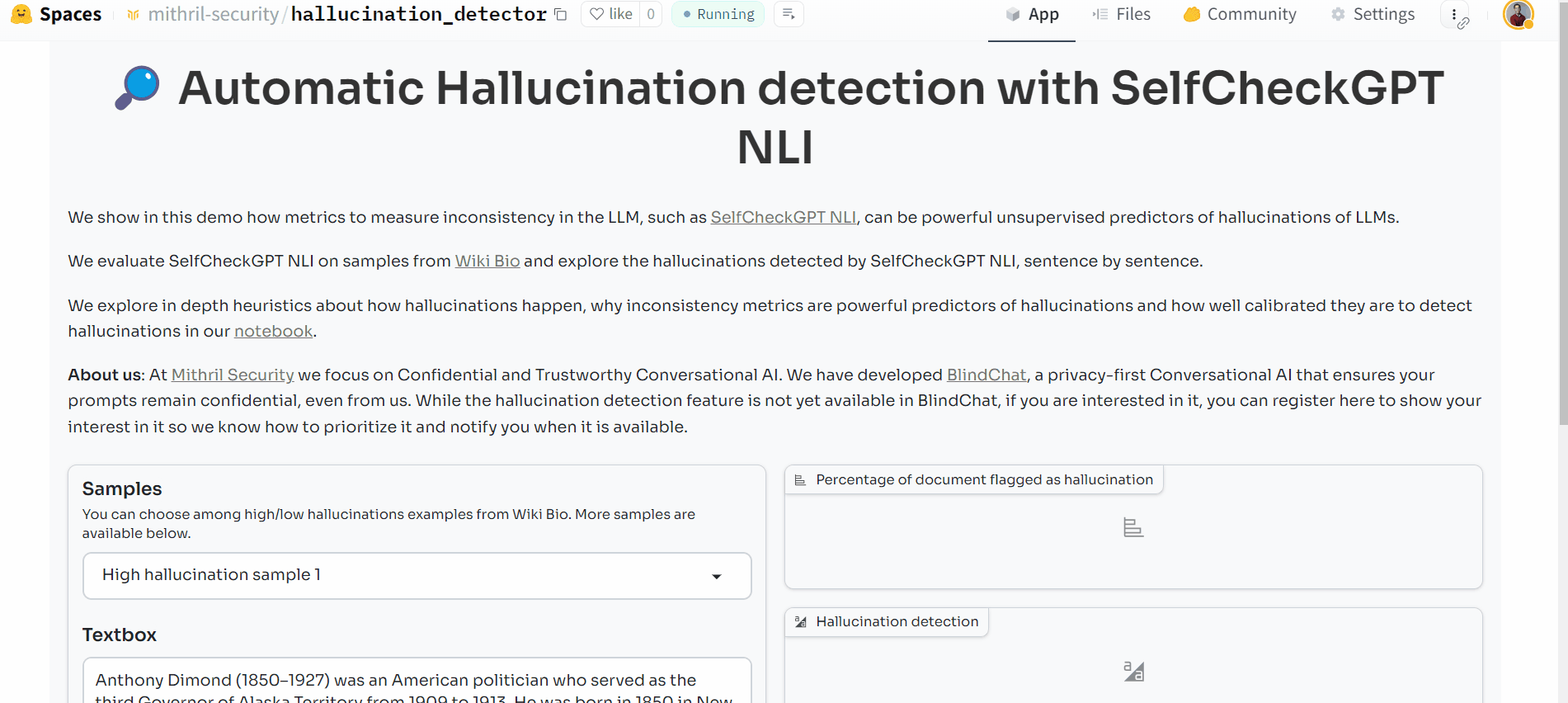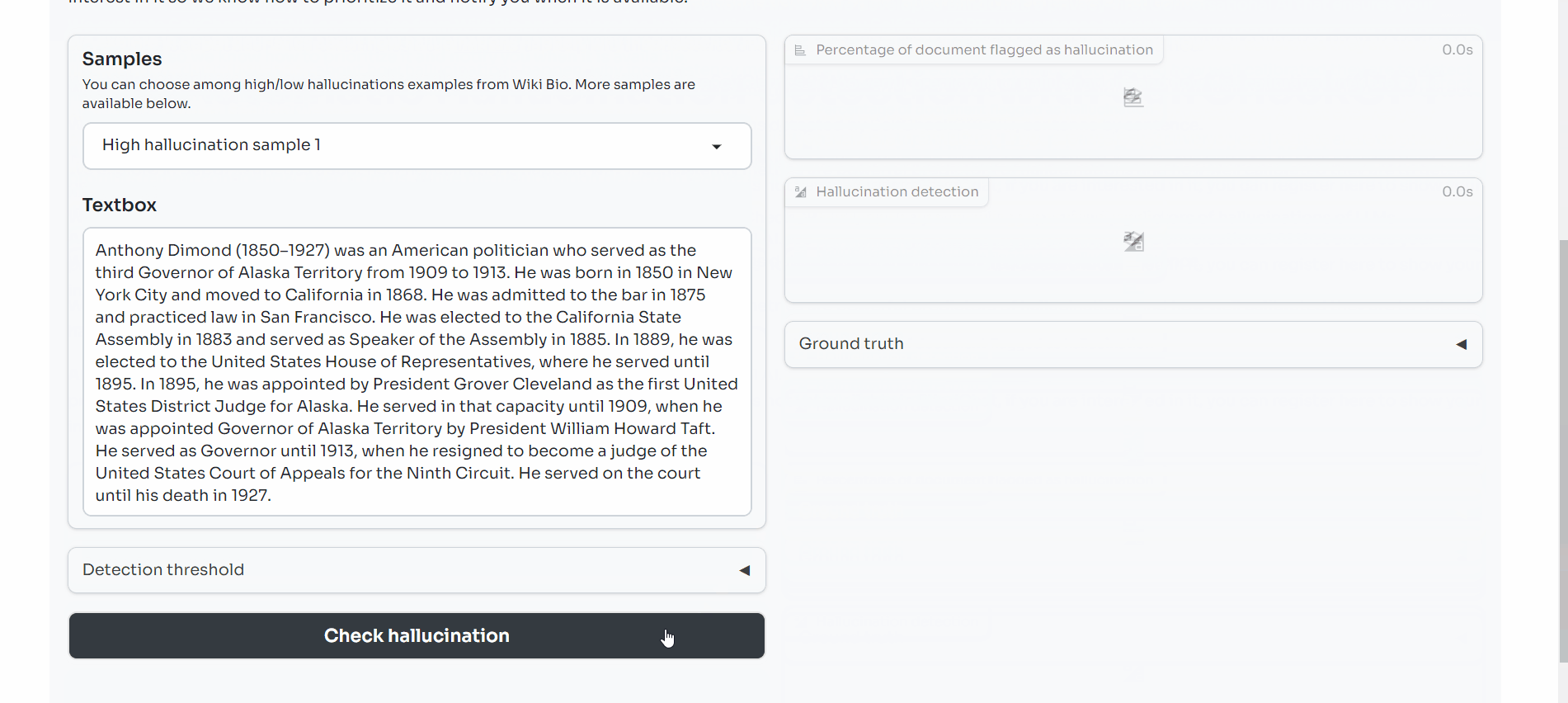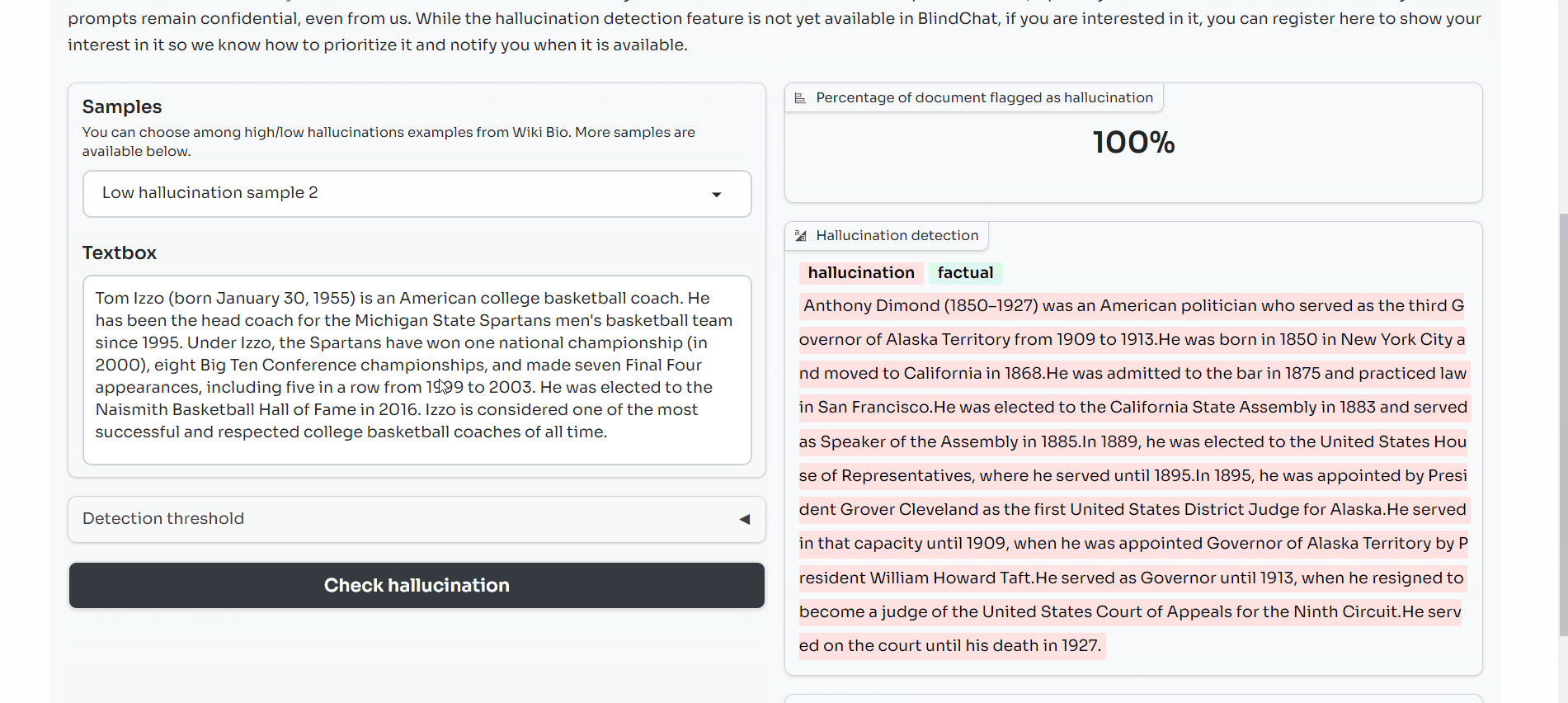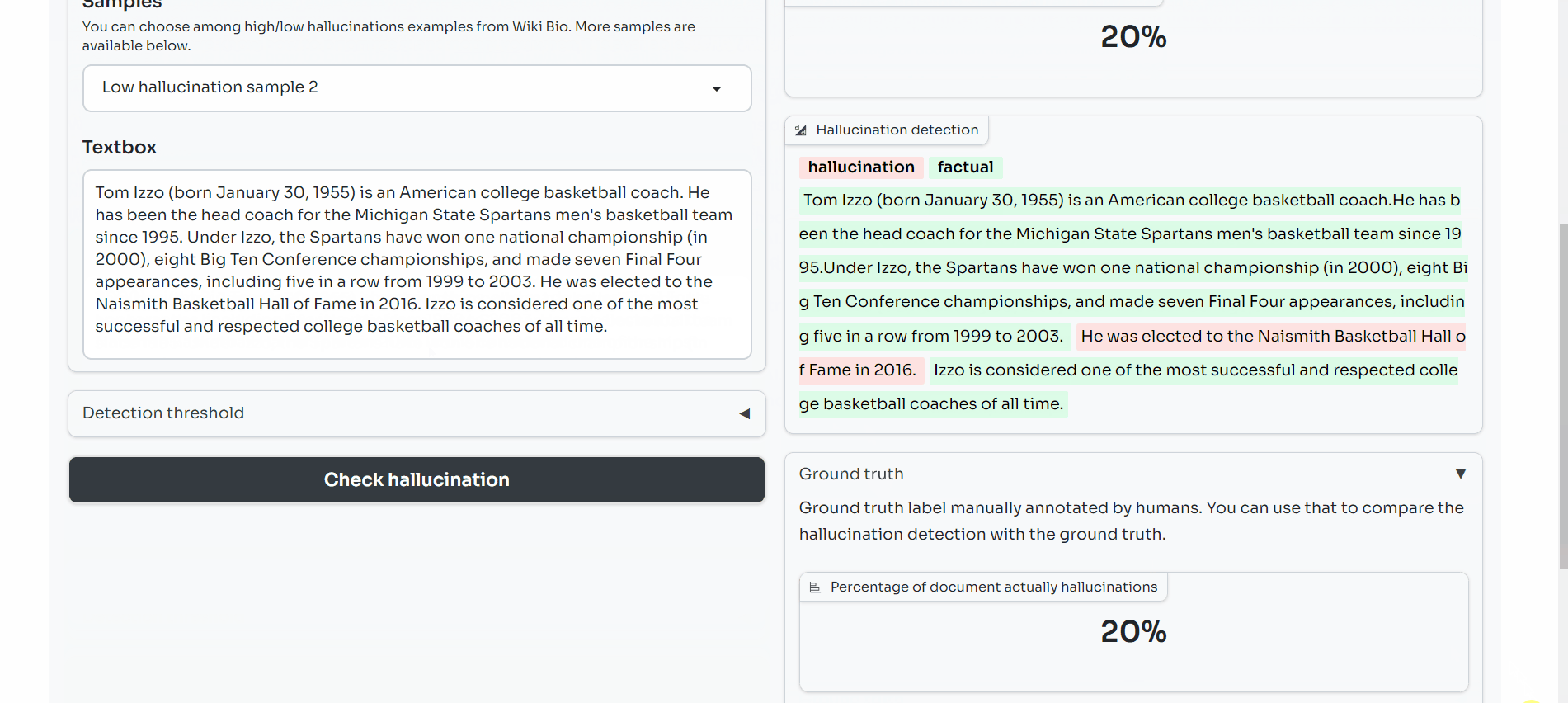
The percentage of detected hallucinations is calculated and provided.
Below the score, you will see the sample highlighted in red where a sentence is flagged as a hallucination (i.e. it had a SelfCheckGPT NLI score equal to or higher than our threshold detection rate) and green where it is not flagged as a hallucination (i.e. its SelfCheckGPT score is below this threshold).
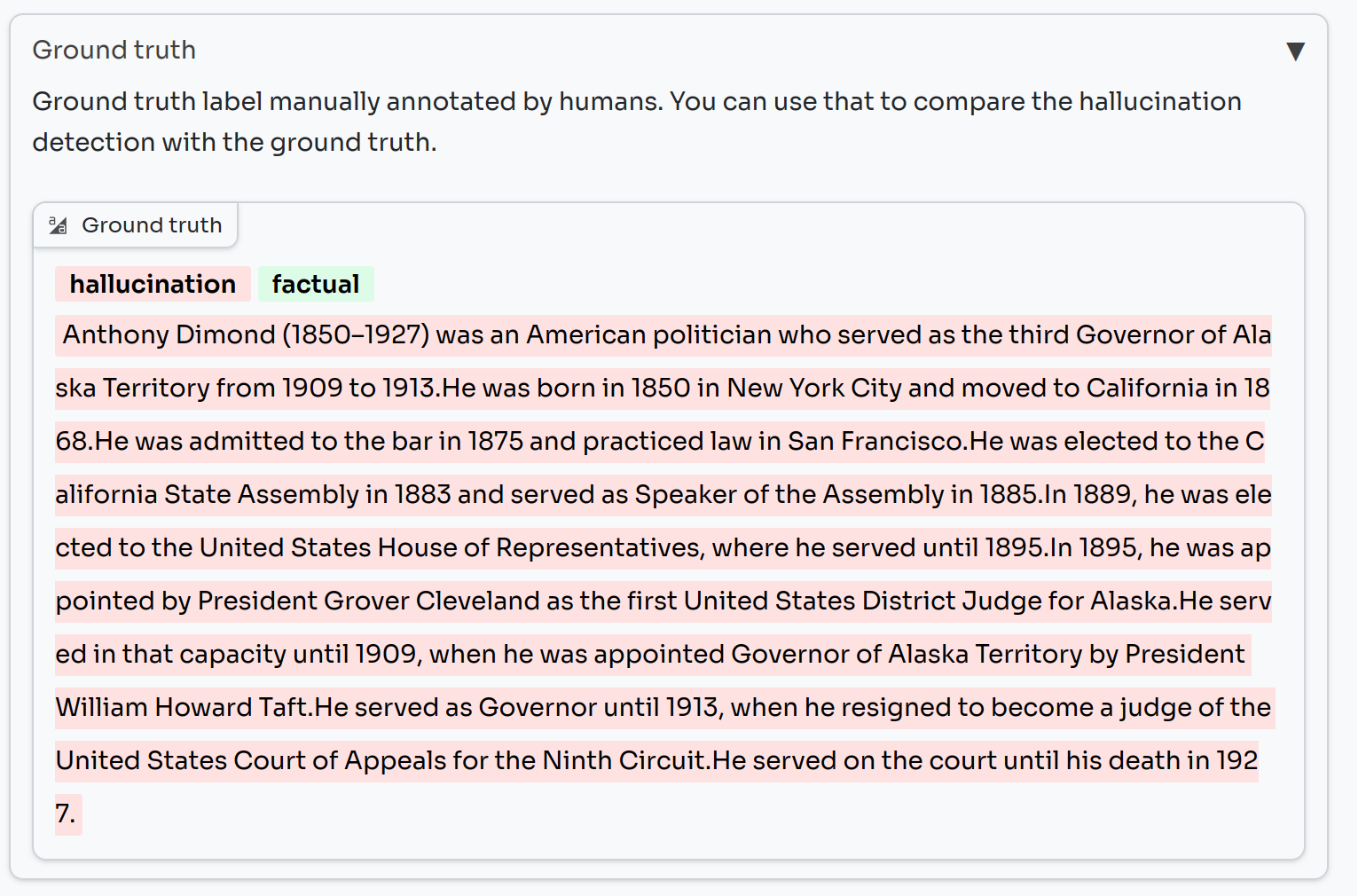
You can visually compare this against the ground truth for each sample, which highlights each sentence according to whether it was labeled as true or false by humans.
Conclusion
While hallucinations are not the only obstacle to building trust in AI, the automatic detection of hallucinations represents a potential great step towards developing more reliable AI systems.
Implementing a sufficiently accurate and sensitive measure for detecting hallucinations in a particular use case can make the difference between a great deployment and an AI actively sharing wrong information with millions of users.
We hope we have provided you with useful insights on LLM hallucinations and the SelfCheckGPT NLI metric in particular.
If you are interested in our other projects to build Confidential and Trustworthy AI, please feel free to check out BlindChat, our privacy-by-design Conversational AI, or get in touch.
Fuente: https://huggingface.co