
Los transformadores han revolucionado el aprendizaje profundo, pero su complejidad de atención cuadrática limita su capacidad para procesar entradas infinitamente largas. A pesar de su eficacia, sufren inconvenientes como olvidar información más allá de la ventana de atención y necesitar ayuda con el procesamiento de contextos prolongados.
Transformers have revolutionized deep learning, yet their quadratic attention complexity limits their ability to process infinitely long inputs. Despite their effectiveness, they suffer from drawbacks such as forgetting information beyond the attention window and needing help with long-context processing. Attempts to address this include sliding window attention and sparse or linear approximations, but they often must catch up at large scales. Drawing inspiration from neuroscience, particularly the link between attention and working memory, there’s a proposed solution: incorporating attention to its latent representations via a feedback loop within the Transformer blocks, potentially leading to the emergence of working memory in Transformers.
Google LLC researchers have developed TransformerFAM, a unique Transformer architecture employing a feedback loop to enable self-attention to the network’s latent representations, facilitating the emergence of working memory. This innovation improves Transformer performance on long-context tasks across various model sizes (1B, 8B, and 24B) without adding weights, seamlessly integrating with pre-trained models. TransformerFAM maintains past information indefinitely, promisingly handling infinitely long input sequences for LLMs. Without introducing new weights, TransformerFAM allows the reuse of pre-trained checkpoints. Fine-tuning TransformerFAM with LoRA for 50k steps significantly enhances performance across 1B, 8B, and 24B Flan-PaLM LLMs.
Prior attempts to incorporate feedback mechanisms in Transformers mainly focused on passing output activations from top layers to lower or intermediate ones, neglecting potential representational gaps. While some research compressed information blockwise, none ensured infinite propagation—recurrent cross-attention between blocks and feedback from upper layers integrated past information to subsequent blocks. To overcome quadratic complexity in Transformer context length approaches like sparse attention and linear approximations were explored. Alternatives to attention-based Transformers include MLP-mixer and State Space Models. TransformerFAM draws inspiration from Global Workspace Theory, aiming for a unified attention mechanism for processing various data types.
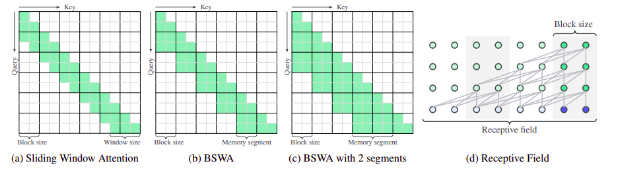
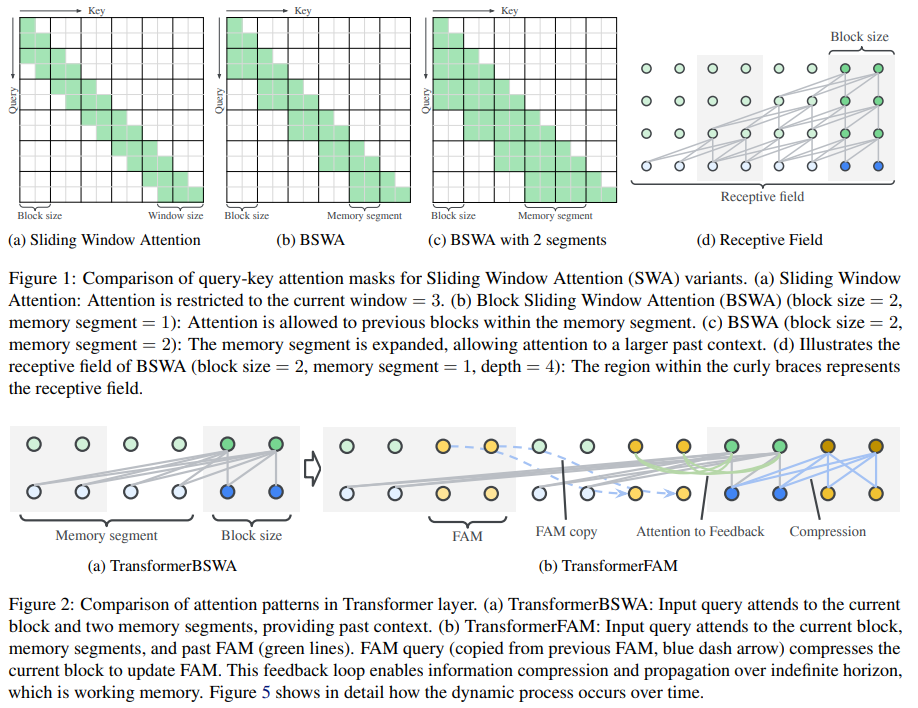
Two primary approaches are commonly employed in handling long-context inputs: increasing computational resources or implementing Sliding Window Attention (SWA). SWA, introduced by Big Bird, partitions the input into blocks, caching information block by block, a strategy termed Block Sliding Window Attention (BSWA). Unlike standard SWA, BSWA attends to all information within the ring buffer without masking out past keys and values. It employs two hyperparameters, block size, and memory segment, to control the size and scope of attended information. While BSWA offers linear complexity compared to the quadratic complexity of standard Transformers, it possesses a limited receptive field. This limitation necessitates further innovation to address long-context dependencies effectively.
FAM is developed in response to this challenge, building upon BSWA’s blockwise structure. FAM integrates feedback activations into each block, dubbed virtual activations, enabling the dynamic propagation of global contextual information across blocks. This architecture fulfills key requirements such as integrated attention, block-wise updates, information compression, and global contextual storage. Incorporating FAM enriches representations and facilitates the propagation of comprehensive contextual information, surpassing the limitations of BSWA. Despite the initial concern of potential inefficiency due to the feedback mechanism, the vectorized map-based self-attention in blocks ensures efficient training and minimal impact on memory consumption and training speed, maintaining parity with TransformerBSWA.
In the movie “Memento,” the protagonist’s struggle with anterograde amnesia parallels the current limitations of LLMs. While LLMs possess vast long-term memory capabilities, their short-term memory is restricted by attention windows. TransformerFAM offers a solution to addressing anterograde amnesia in LLMs, leveraging attention-based working memory inspired by neuroscience. The study hints at a path toward resolving the memory challenge in deep learning, a crucial precursor to tackling broader issues like reasoning.
Fuente: https://www.marktechpost.com