
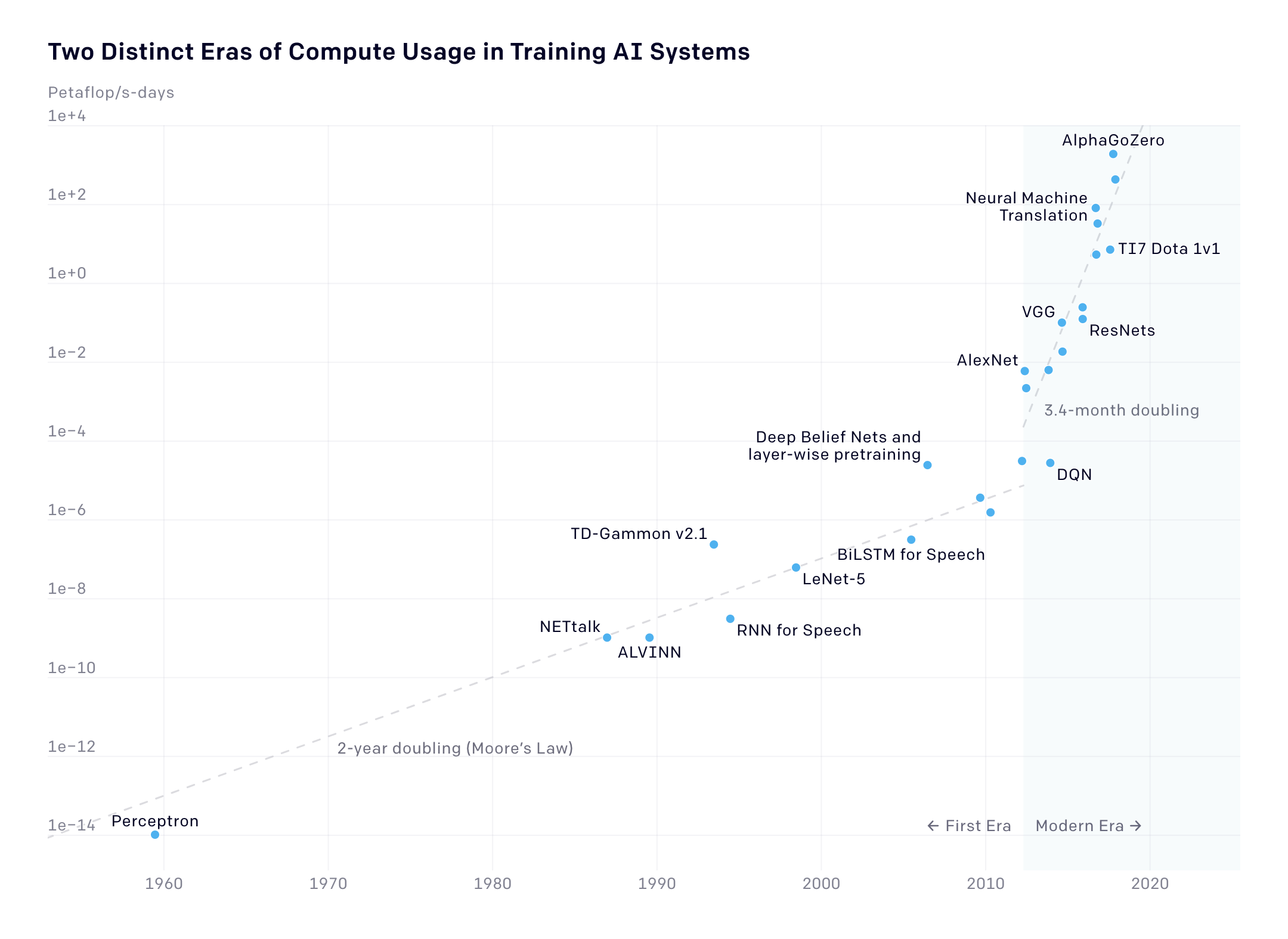
Históricamente, la potencia computacional requerida para entrenar sistemas de inteligencia artificial se duplicaba cada dos años, pero ahora lo hace cada 3,4 meses, siete veces más rápido, una tendencia que no hace más que aumentar la brecha de capacidades entre investigadores públicos y privados.
En 2018, OpenAI descubrió que la cantidad de potencia computacional necesaria para entrenar modelos de inteligencia artificial (IA) más grandes se duplica cada 3,4 meses desde 2012.
Un año después, el laboratorio de investigación de IA de San Francisco (EE. UU.) añadió nuevos datos a su análisis y demostró cómo el aumento posterior a 2012 se compara con el tiempo de duplicación histórica desde los inicios del campo. Desde 1959 hasta 2012, la cantidad de energía requerida se duplicaba cada dos años, siguiendo la Ley de Moore. Esto significa que el aumento de la potencia de hoy en día es más de siete veces mayor que la tasa anterior.
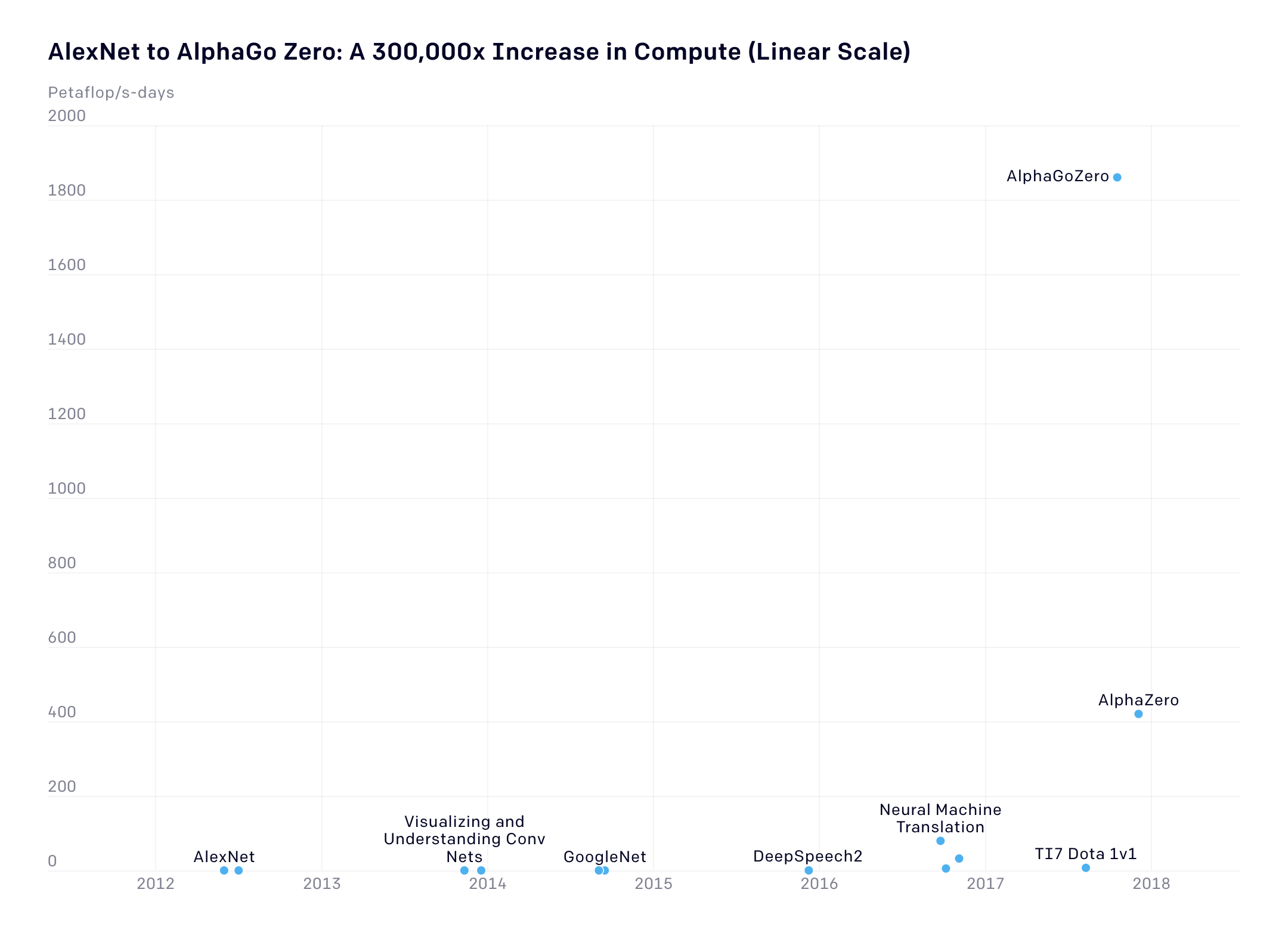
Este drástico aumento en los recursos computacionales necesarios subraya lo caros que se han vuelto los logros del campo. Habrá que tener en cuenta que el gráfico anterior muestra una escala logarítmica. En una escala lineal (abajo), se puede ver más claramente cómo el uso computacional se ha incrementado 300.000 veces en ese periodo de siete años.
El gráfico no incluye algunos de los avances más recientes, como el modelo de lenguaje a gran escala de Google BERT, el modelo de lenguaje GPT-3 de OpenAI y el modelo de juego StarCraft II de DeepMind, AlphaStar, y los modelos aún más grandes desarrollados el año pasado.
Dada esta tendencia hacia modelos cada vez más grandes y, por tanto, con mayor consumo computacional, está provocando que cada vez más investigadores alerten sobre los enormes costes del aprendizaje profundo. En 2019, un estudio de la Universidad de Massachusetts en Amherst (EE. UU.), mostró cómo estos crecientes costos computacionales se traducen directamente en emisiones de carbono.
El artículo también señala cómo esta tendencia intensifica la privatización de la investigación de inteligencia artificial porque socava la capacidad de los laboratorios académicos de competir con los privados más ricos en recursos.
En respuesta a esta creciente preocupación, varios grupos de la industria han empezado a lanzar recomendaciones. El Instituto Allen de Inteligencia Artificial, una empresa de investigación sin ánimo de lucro en Seattle (EE. UU.), ha propuesto que los investigadores publiquen los costes económicos y computacionales del entrenamiento de sus modelos junto con sus resultados de rendimiento, por ejemplo.
En su propio blog, OpenAI sugirió que los formuladores de políticas deberían aumentar los fondos para los investigadores académicos para cerrar la brecha de recursos entre los laboratorios académicos y los de la industria.
Fuente: https://www.technologyreview.es