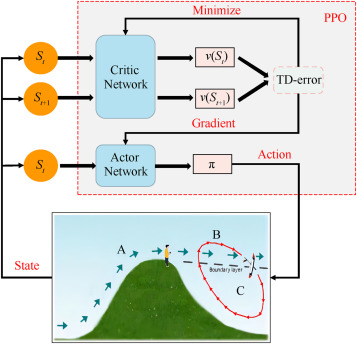
Este texto analiza un nuevo enfoque para el vuelo dinámico de vehículos aéreos no tripulados (UAV), inspirado en aves como los albatros. El vuelo dinámico utiliza campos de viento para mejorar el alcance de los UAV mediante la optimización de las trayectorias de vuelo. El artículo presenta un método de aprendizaje de refuerzo profundo (DRL) para mejorar la planificación y optimización de trayectorias, abordando los desafíos de los métodos existentes que se basan en valores iniciales difíciles de determinar. La trayectoria se parametriza utilizando funciones de base de Fourier, lo que permite una representación flexible con menos parámetros. El problema de optimización se enmarca como un proceso de toma de decisiones de Markov, con el algoritmo de Optimización de Política Proximal (PPO2) utilizado para optimizar la trayectoria. Los resultados muestran que este nuevo enfoque produce trayectorias más suaves y reduce las métricas de rendimiento clave (empuje, diferencia de empuje y diferencia de velocidad aerodinámica) hasta en un 39%, en comparación con los métodos de programación no lineal tradicionales.
Abstract
Dynamic soaring, inspired by the wind-riding flight of birds such as albatrosses, is a biomimetic technique which leverages wind fields to enhance the endurance of unmanned aerial vehicles (UAVs). Achieving a precise soaring trajectory is crucial for maximizing energy efficiency during flight. Existing nonlinear programming methods are heavily dependent on the choice of initial values which is hard to determine. Therefore, this paper introduces a deep reinforcement learning method based on a differentially flat model for dynamic soaring trajectory planning and optimization. Initially, the gliding trajectory is parameterized using Fourier basis functions, achieving a flexible trajectory representation with a minimal number of hyperparameters. Subsequently, the trajectory optimization problem is formulated as a dynamic interactive process of Markov decision-making. The hyperparameters of the trajectory are optimized using the Proximal Policy Optimization (PPO2) algorithm from deep reinforcement learning (DRL), reducing the strong reliance on initial value settings in the optimization process. Finally, a comparison between the proposed method and the nonlinear programming method reveals that the trajectory generated by the proposed approach is smoother while meeting the same performance requirements. Specifically, the proposed method achieves a 34% reduction in maximum thrust, a 39.4% decrease in maximum thrust difference, and a 33% reduction in maximum airspeed difference.

Fuente: https://www.sciencedirect.com